
Model Highlight: Qwen3 4B
Qwen3 4B punches above its weight—delivering medium-model performance in a compact, efficient package. Here’s how it stacks up on key benchmarks.


This is the first post in a new short-form series highlighting different models, benchmarks, and generalized trends on the Atlas platform. We expect this to be more of a traditional newsletter—keeping you updated on the latest AI models (and how well they stack up) without having to read through 20 different model cards or release announcements.
Qwen 3 4B: A new frontier
Last week, Alibaba announced the smallest version of their premier open-source series, Qwen 3, with the release of Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507.
In an ecosystem increasingly dominated by parameter counts in the hundreds of billions, these compact models present a compelling data point for the ongoing debate about model efficiency versus raw scale.
The 4B parameter class has emerged as a critical benchmark for edge deployment and resource-constrained environments—small enough to run on consumer hardware with a single GPU, yet sophisticated enough to handle complex reasoning tasks that would have required orders of magnitude more parameters just eighteen months ago.
With native 256K context windows and the ability to toggle between standard inference and explicit chain-of-thought reasoning, these models represent a fascinating test case for quantifying the actual performance-per-parameter gains achieved through modern training methodologies.
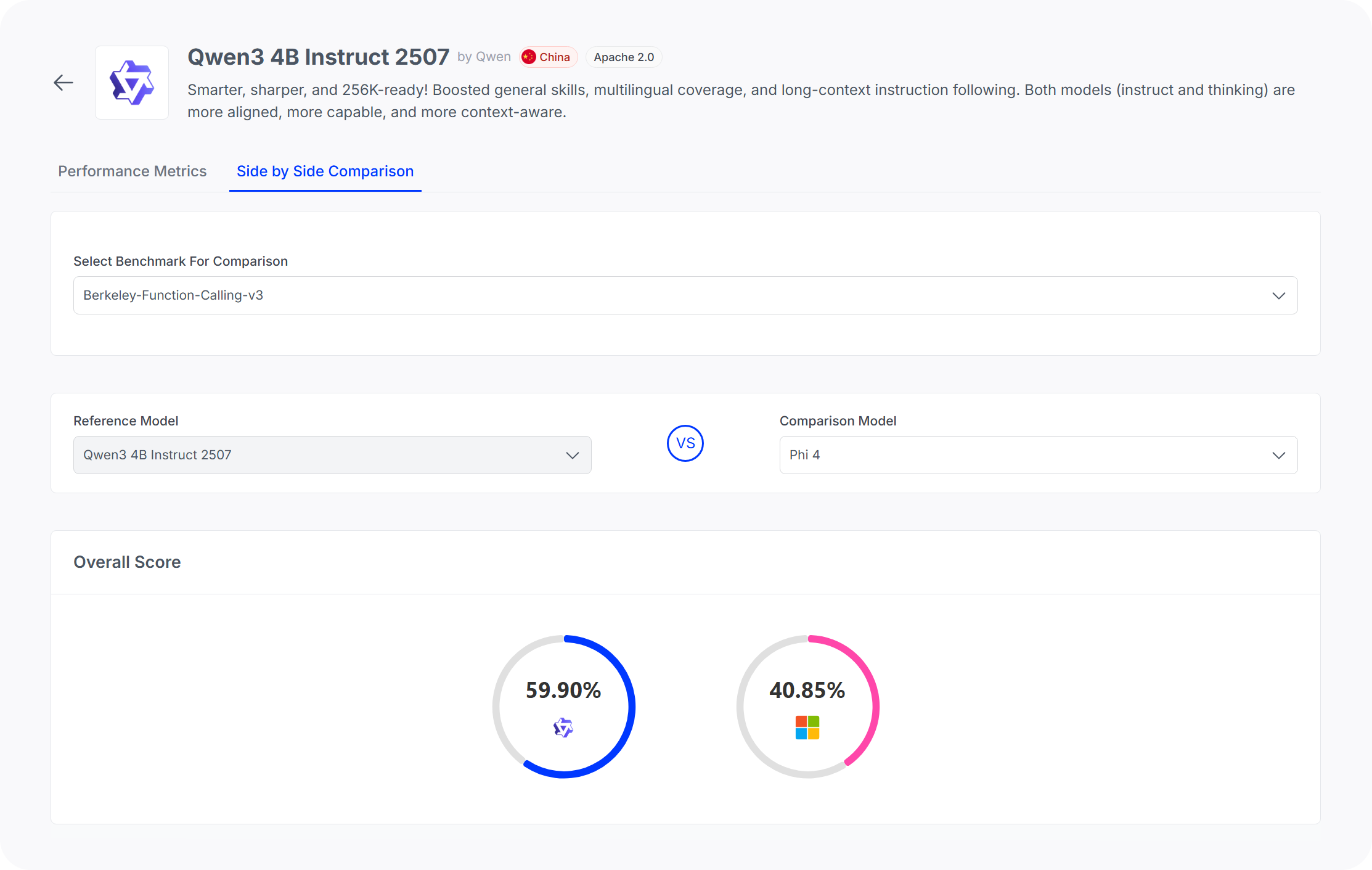
What makes this release particularly interesting from a quantitative perspective is its performance on difficult, agentic tasks relative to its size.
On Berkeley Function Calling—a benchmark designed to measure model performance in real-world environments—Qwen3 outperforms medium-sized models such as Phi-4.
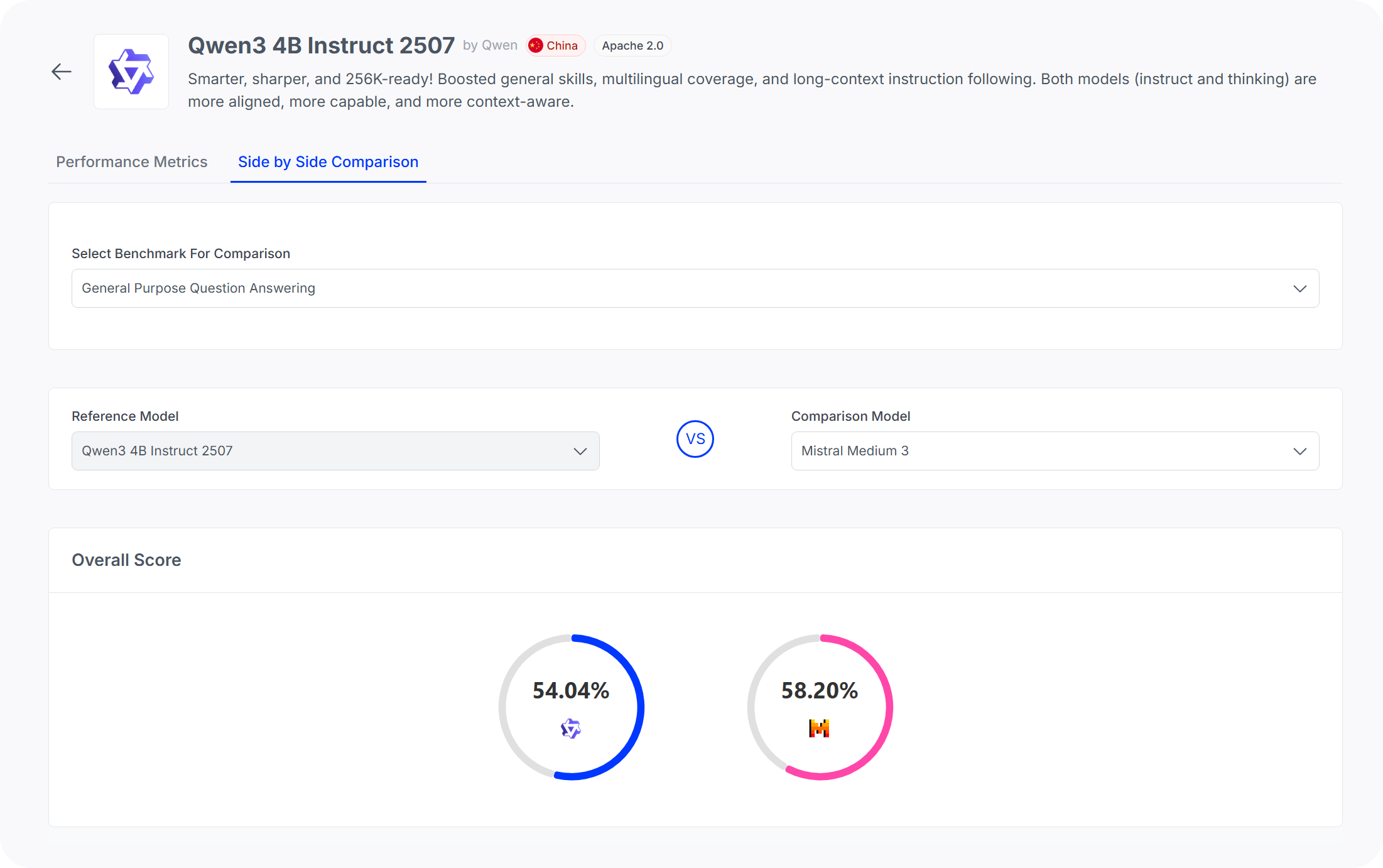
The Qwen3-4B results reinforce an emerging pattern in the post-reasoning era: architectural innovations and training methodologies are delivering compound improvements that fundamentally alter the performance-to-parameter scaling laws we've relied on for resource planning.
When a 4B parameter model approaches or exceeds the benchmark scores of models 10–20x its size from just one generation ago, it forces a recalculation of deployment strategies and cost–benefit analyses across the entire inference stack.
Perhaps more significantly, these efficiency gains arrive just as the industry grapples with the practical limits of scaling—both in terms of training compute availability and inference economics.
The ability to achieve frontier-adjacent performance on consumer-grade hardware democratizes not just access but experimentation, potentially accelerating the feedback loop between research and production deployment.