


Welcome to this week’s edition of InFocus, our weekly newsletter on analyzing the latest trends in AI model releases, and how well they stack up based on our internal quantitative analysis through Atlas, our platform for executing benchmarks at scale.
GPT 5: A frontier series from OpenAI
Last week, OpenAI released their long-anticipated series of GPT 5 series models, with a mini, nano, and mainstream version being available both in the ChatGPT interface and through the API. While the release was somewhat controversial based on initial limits OpenAI applied to its reasoning models (and for its depreciation of GPT 4o), it soon rose to the top of preferred models, as rated by its ability to solve agentic and coding tasks.
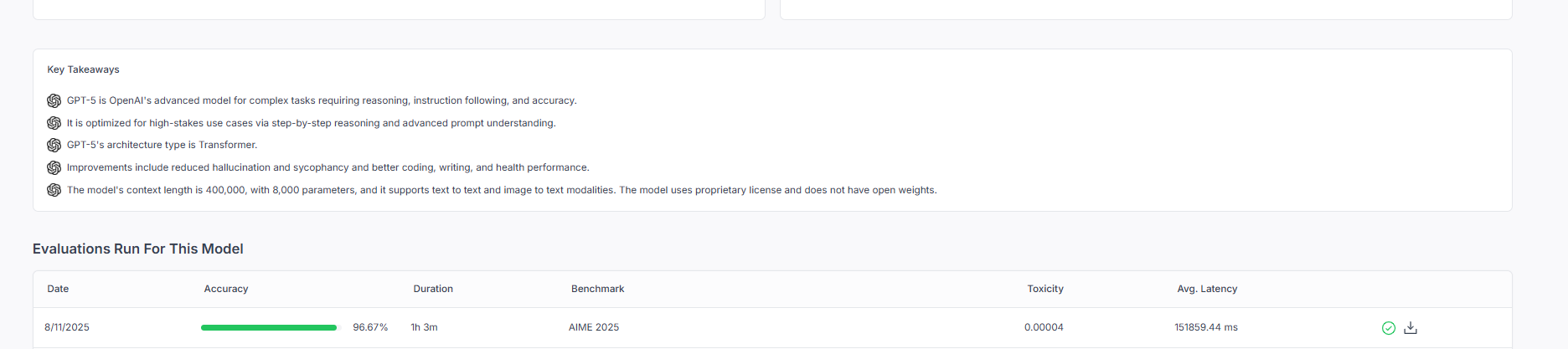
As always, we ran several benchmarks against all versions of GPT-5: as expected, it is quite powerful on quantitative tasks such as mathematics and generalized reasoning. Most notably, it scored a 96.67% on AIME 2025, signifying not only its advanced mathematics capabilities, but also that AIME itself may have become saturated just a couple of months after release.
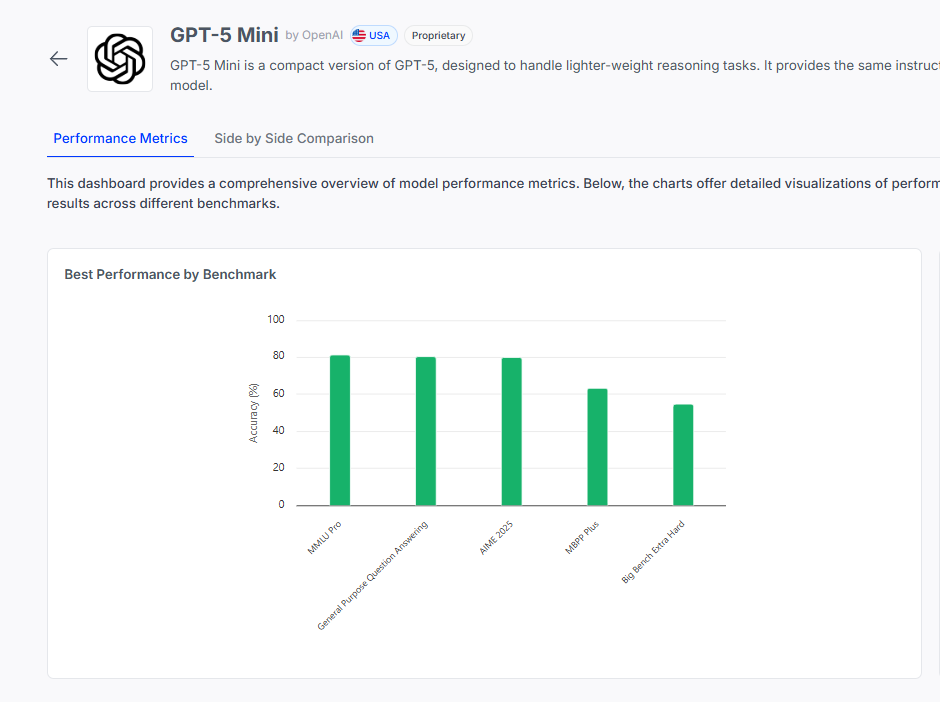
GPT 5 mini also holds it own, providing advanced capabilities at a low cost. It scores over an 80% on MMLU Pro and an 80% on GPQA, signifying its advanced knowledge on graduate level topics.
GPT-5’s release, despite raising some eyebrows due its rollout, is without a doubt an extremely impressive model with frontier capabilities, as evidenced by its performance on baseline, knowledge-based benchmarks. As always, we will continue bringing you more analysis through benchmarks as time goes on, including GPT 5’s performance on agentic benchmarks.