
In Focus: GLM 4.5 Release | Issue 9
GLM 4.5 is here—and it’s already topping the charts. We ran it through Atlas to see how Z.ai’s latest stacks up in reasoning, tool use, and real-world performance.


Welcome! This will be the 9th edition of our In Focus series focusing on new releases for frontier models and benchmarks. In this post, we are diving deep into GLM 4.5 a new series of frontier models released by Z.ai, a leading Chinese artificial intelligence company. GLM 4.5 and its cousin, GLM 4.5 AIR, are foundational models optimized for agentic intelligence. As always, we ran an initial set of early evaluations from our benchmark repository on Atlas, and have some early analysis to share.
Background
Z.ai is another Chinese AI model company that, like DeepSeek before it, has gone somewhat under the radar. They have a wide range of models, from an initial lightweight reasoning model (GLM 4.1 V) to their own version of Deep Research (Rumination). This past week, they announced their latest series of models: GLM 4.5. GLM 4.5 is specifically designed for frontier intelligence on agentic, practical tasks. GLM-4.5 has 355 billion total parameters, while GLM 4.5 AIR is slightly smaller, with 106 billion total parameters. Both models made waves upon launch, immediately launching to the top of multiple public leaderboards, and unlike other recent releases, seeming to excel at reasoning, mathematics, programming, and agentic workflows.
GLM 4.5 at a glance
GLM 4.5 outperforms Minimax, Qwen 3, and R1 on agentic tool use, as evidenced by its score on Berkley Function Calling. This indicates that GLM’s optimization for agentic use-cases is valid, and is leading to practical performance improvements. Berkley Function Calling measures the extent to which models can use tools to interact with and fetch real-world data.
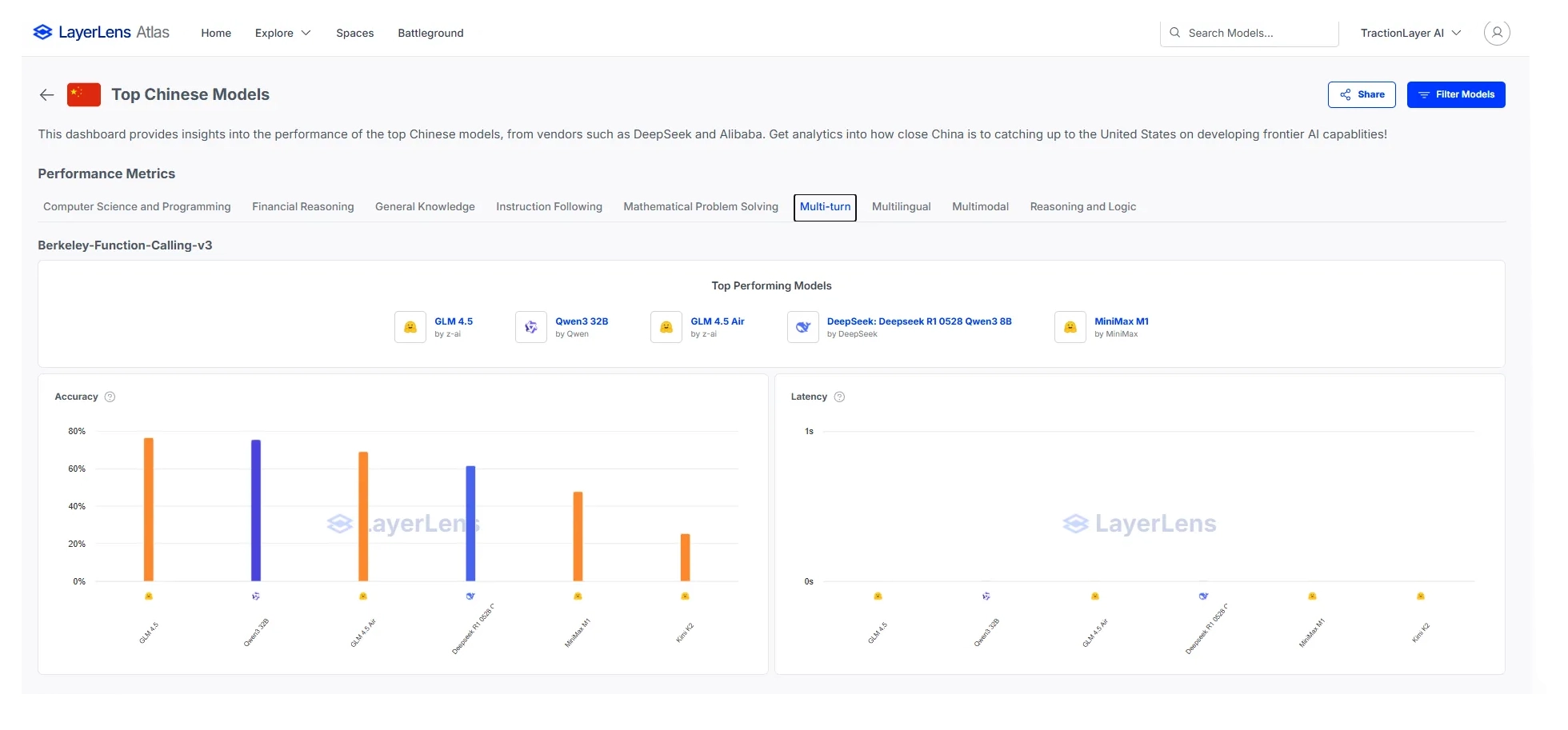
GLM 4.5 achieves this without compromising performance on traditional knowledge-based benchmarks such as GPQA. On the GPQA benchmark, GLM outperforms DeepSeek V3 significantly, indicating that it can perform quite well on graduate-level tests.
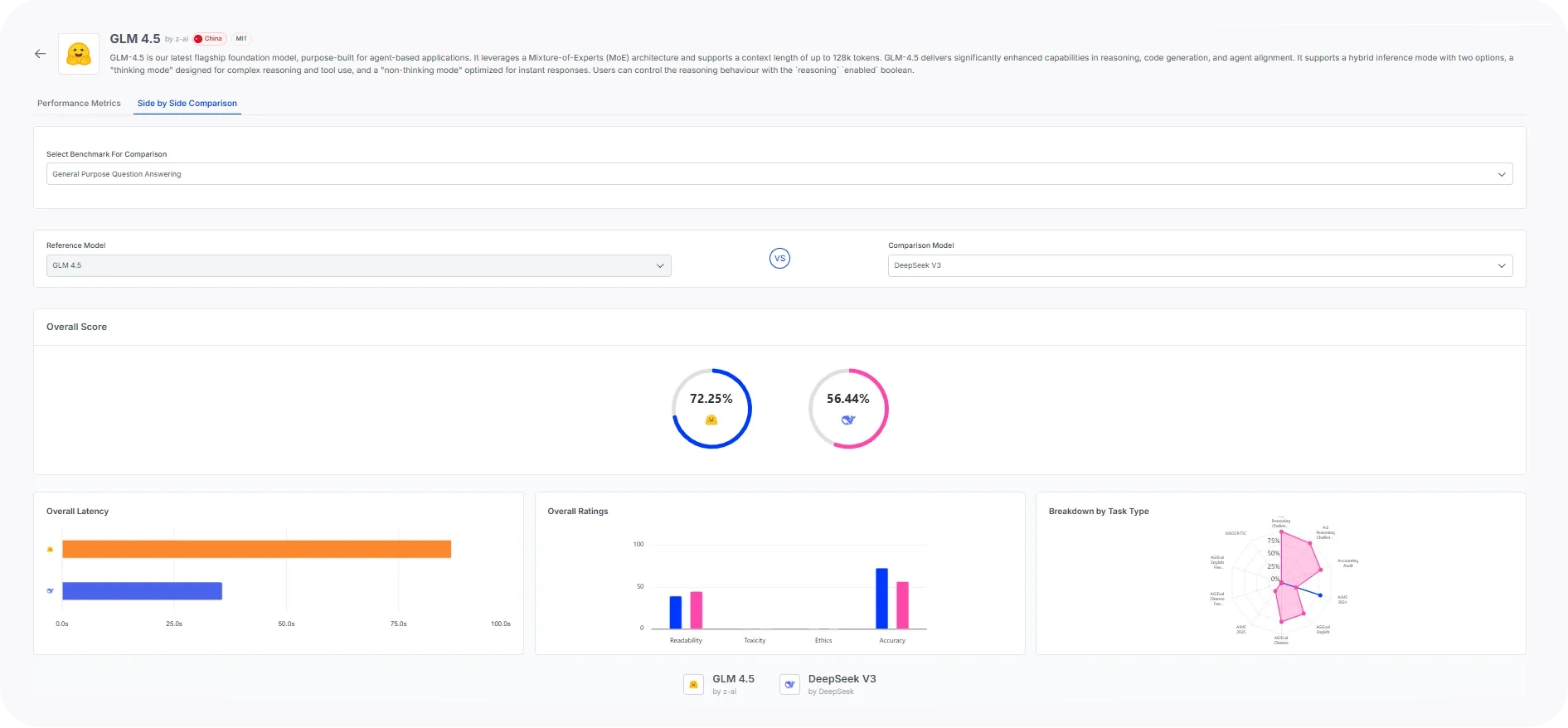
What’s next?
These early results serve as yet another indication that Chinese models have caught up with the United States. Z.ai is the latest addition to a growing list of AI companies building frontier intelligence models.
At LayerLens, we are committed to tracking this progress. We will be continuing to evaluate GLM models, and other new releases, directly on Atlas.