
A deep dive into Terminal Bench
Terminal Bench is the latest agentic benchmark available on Atlas

Agentic benchmarks are evaluations that measure the ability of a language model to effectively take actions and complete tasks within a constrained, practical environment. Rather than traditional Q&A, which mostly measures the ability of a model to recall and output the appropriate output to a static input. Agentic benchmarks provide as input a set of tasks, an environment with a specific set of tools, and a format that allows the model to interact with said environment. The model, or agent, is measured on its ability to successfully execute the task.
Terminal-Bench: Technical Deep Dive and the Evolution of Agent Evaluation
Terminal-Bench (terminal-bench-core==0.1.1) represents a significant milestone in AI agent evaluation, addressing a critical gap in how we measure artificial intelligence systems' practical capabilities. While most AI benchmarks focus on language understanding, reasoning, or specific domain knowledge, Terminal-Bench takes a different approach by evaluating something more fundamental: can AI agents actually operate effectively in the computing environments they're meant to assist with?
The Need for Terminal Mastery Evaluation
The development of Terminal-Bench emerged from a growing recognition in the AI community that impressive performance on traditional benchmarks doesn't necessarily translate to real-world utility. An AI system might excel at answering questions about programming concepts or even generating syntactically correct code, but struggle when asked to navigate file systems, manage processes, or execute complex multi-step terminal operations that working developers perform daily.
Terminal environments represent one of the most direct interfaces between humans and computing systems. They require not just knowledge of commands and syntax, but an understanding of system state, file hierarchies, process management, and the ability to chain operations together coherently. For AI agents to be truly useful as coding assistants or system administrators, they need to demonstrate genuine terminal mastery rather than just theoretical knowledge.
Architecture and Evaluation Framework
Terminal-Bench provides agent makers with a comprehensive evaluation harness designed specifically for quantifying terminal mastery. The benchmark suite appears to test agents across multiple dimensions of terminal interaction, from basic command execution to more complex multi-step operations that require maintaining context and understanding system state changes.
The evaluation methodology captures both accuracy and latency metrics, recognizing that practical terminal usage requires not just correct responses but reasonable response times. The nanosecond-level precision in latency measurements suggests the benchmark is designed to evaluate real-time agent performance rather than batch processing scenarios.
Current State of the Field
The LayerLens Atlas platform results reveal some fascinating insights about the current landscape of AI agent capabilities. GLM 4.5 by z-ai currently leads with 41.25% accuracy, demonstrating the effectiveness of its Mixture-of-Experts (MoE) architecture in handling the complex reasoning required for terminal operations. The model's design optimization for agent-based applications, enhanced reasoning capabilities, and code generation appears to translate directly to better terminal performance.
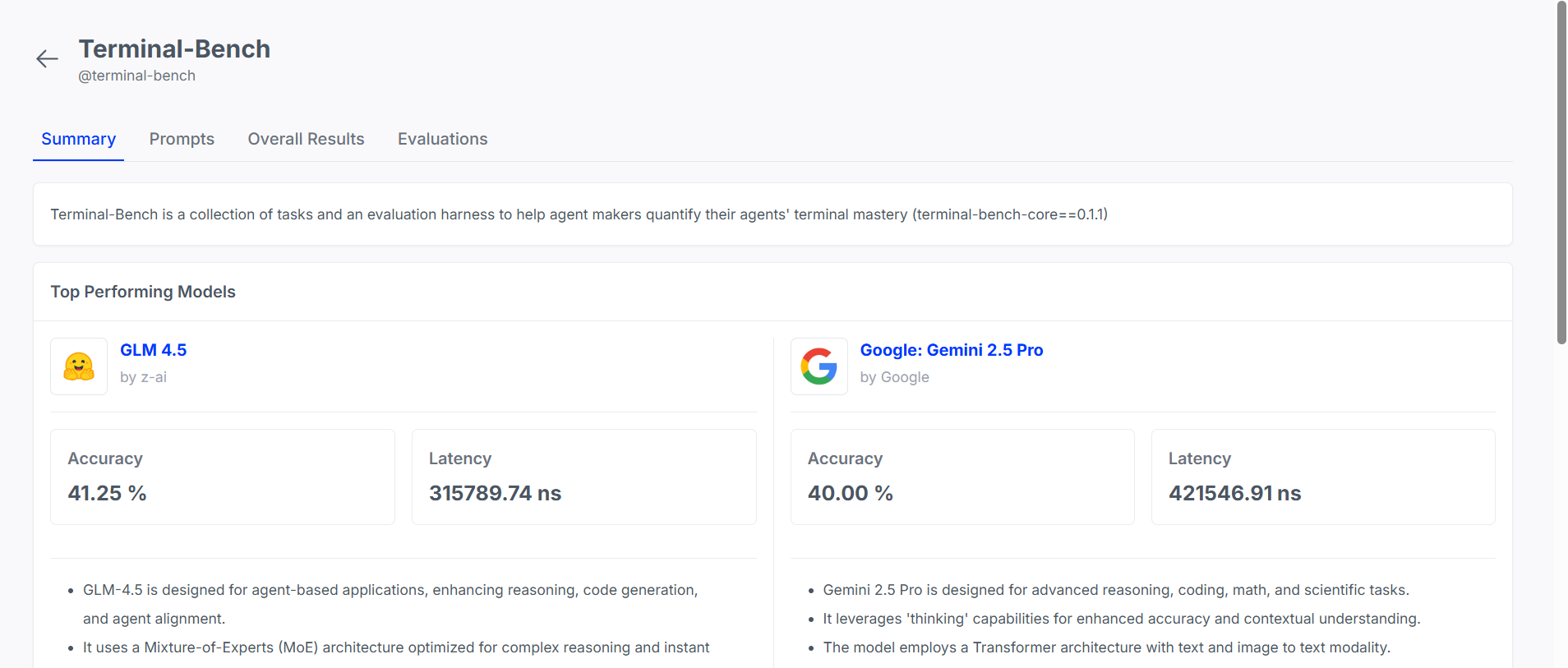
However, the 315,789.74 nanosecond latency suggests there's still computational overhead involved in achieving this level of accuracy. This latency-accuracy tradeoff becomes even more apparent when comparing to Google's Gemini 2.5 Pro, which achieves comparable accuracy (40.00%) but at a significant latency cost of 421,546.91 nanoseconds.
Technical Implications and Model Architecture
The performance characteristics reveal interesting insights about different architectural approaches to terminal mastery. GLM 4.5's MoE design appears particularly well-suited for the diverse range of skills required in terminal environments. The mixture-of-experts approach allows the model to specialize different expert networks for different types of terminal operations, whether they involve file manipulation, process management, text processing, or system administration tasks.
Gemini 2.5 Pro's emphasis on "thinking" capabilities through its enhanced Transformer architecture with text and image-to-text modality suggests a different approach. The model appears to dedicate more computational resources to reasoning through terminal operations, which may explain both its competitive accuracy and higher latency. The multimodal capabilities could be particularly valuable for terminal scenarios that involve interpreting visual output or understanding complex terminal interfaces.
Performance Distribution and Market Reality
The accuracy versus latency scatter plot reveals the harsh reality of current AI capabilities in terminal environments. The performance distribution shows most models clustering between 200-350 seconds of latency, with accuracy scores spanning a dramatic range from barely functional to moderately capable.
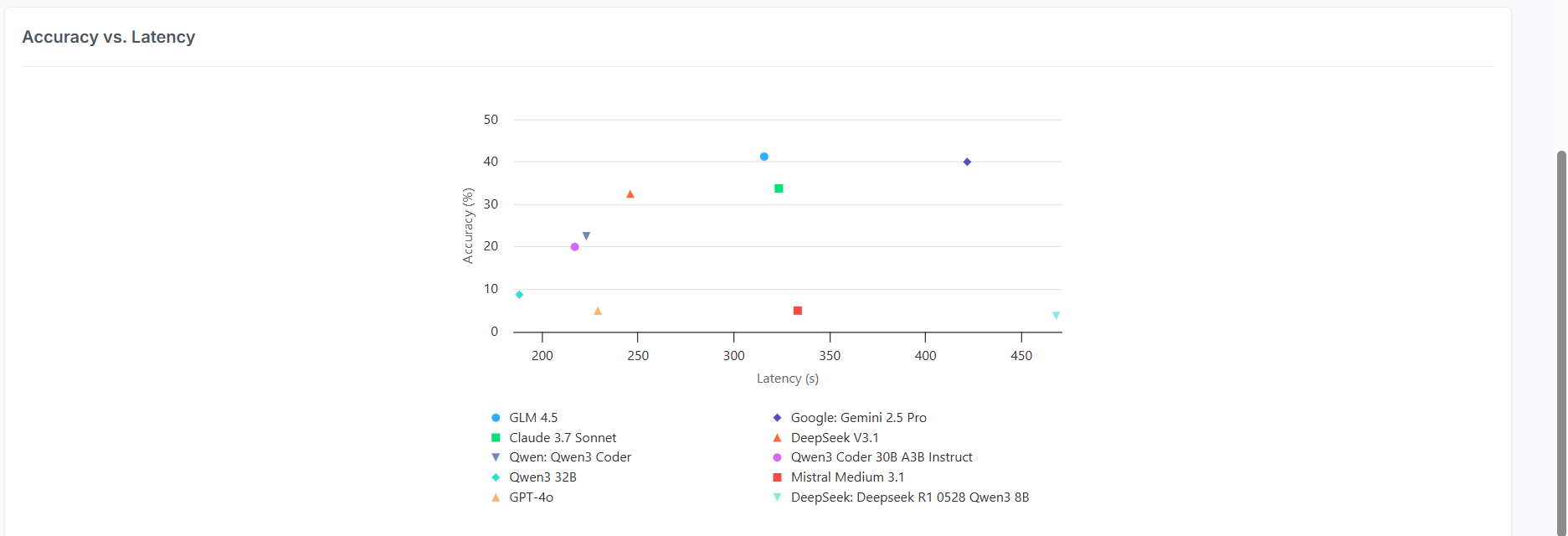
Claude 3.7 Sonnet's position at approximately 35% accuracy with ~330 seconds latency represents a solid middle-ground performance, while the presence of several high-profile models in the single-digit accuracy range highlights how challenging terminal mastery remains. Models like GPT-4o and Mistral Medium 3.1 scoring around 5% accuracy demonstrates that general language capabilities don't automatically translate to terminal proficiency.
The fact that even the best-performing models achieve less than 42% accuracy underscores both the complexity of terminal operations and the significant opportunities for improvement in this domain. These results suggest that terminal mastery involves not just understanding commands and syntax, but requires genuine comprehension of system behavior, state management, and the ability to adapt to dynamic computing environments.
Future Implications
Terminal-Bench's emergence as an evaluation framework reflects the AI community's growing focus on practical, real-world capabilities rather than purely academic benchmarks. The results suggest we're still in the early stages of developing truly capable AI agents for terminal environments, with substantial room for architectural innovations and training improvements.
The performance data indicates that achieving reliable terminal mastery will likely require specialized training approaches, possibly incorporating more interactive learning methodologies that allow models to develop genuine understanding of system behaviors rather than pattern matching on command sequences. The latency considerations also suggest that practical deployment will require careful optimization to balance capability with responsiveness.
As AI agents become more integrated into development workflows and system administration tasks, benchmarks like Terminal-Bench will become increasingly critical for evaluating and comparing different approaches to building capable AI assistants.